
AI/ML – Як система прогнозує аварії в мереж
Як система прогнозує аварії в мережі ще до появи скарг абонентів
У сучасній мережі провайдера недостатньо просто збирати показники з обладнання. Значно важливіше – вчасно зрозуміти, коли вузол починає працювати нестабільно, навіть якщо він ще не перейшов у аварійний стан.
Саме для цього система використовує три незалежні модулі аналізу:
- MetricPredictor – контролює сервери, комутатори, маршрутизатори, ДБЖ, кліматичне обладнання та інші інженерні системи.
- OnuPredictor – аналізує стан абонентських ONU в мережах GPON/EPON.
- SfpPredictor – відстежує роботу SFP/SFP+ модулів та магістральних оптичних ліній.
На відміну від класичних систем моніторингу, вониалгоритми ML реагують не лише на перевищення порогів, а й аналізують тренди, швидкість зміни параметрів та взаємозв'язок між різними показниками. Завдяки цьому система здатна попереджати про проблеми ще до появи аварії або звернення абонентів.
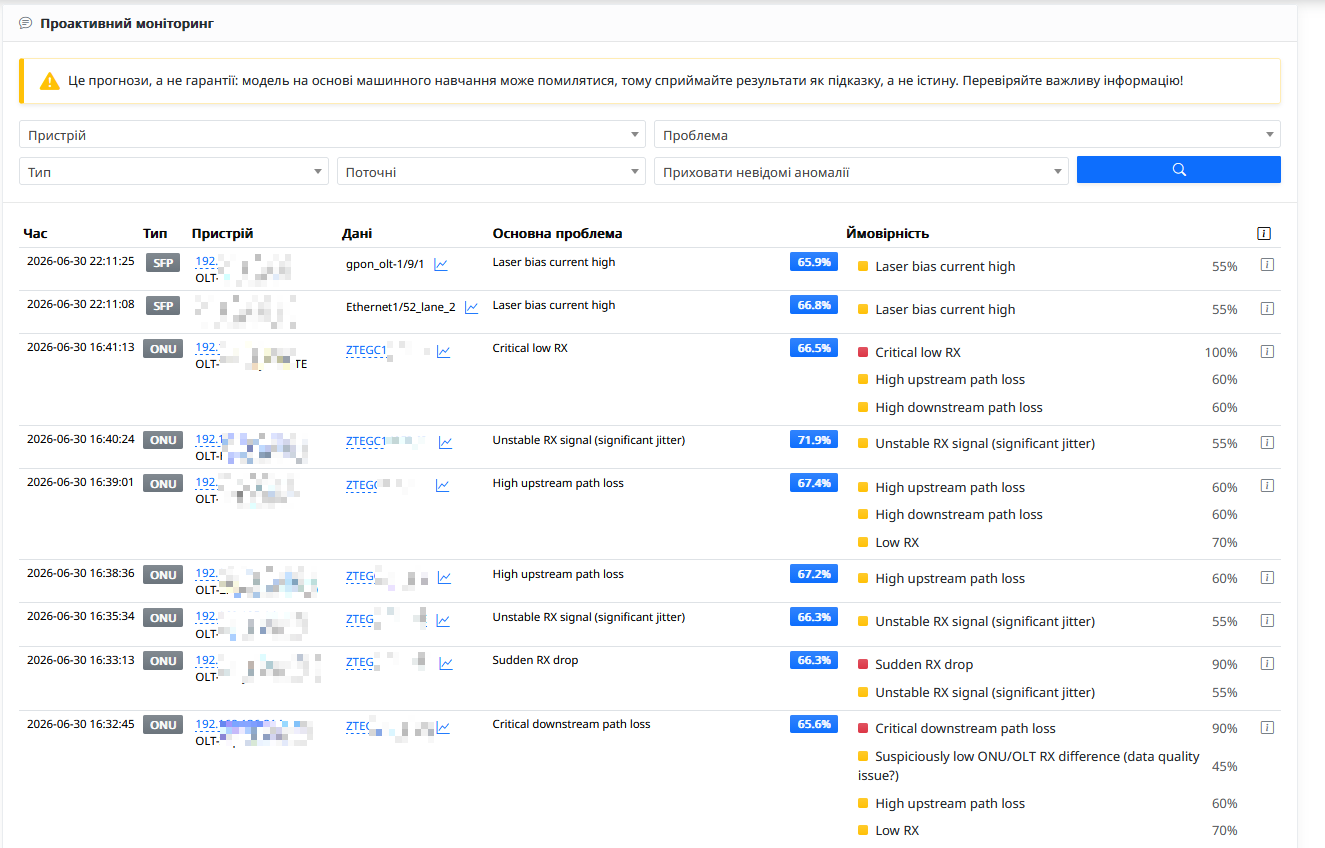
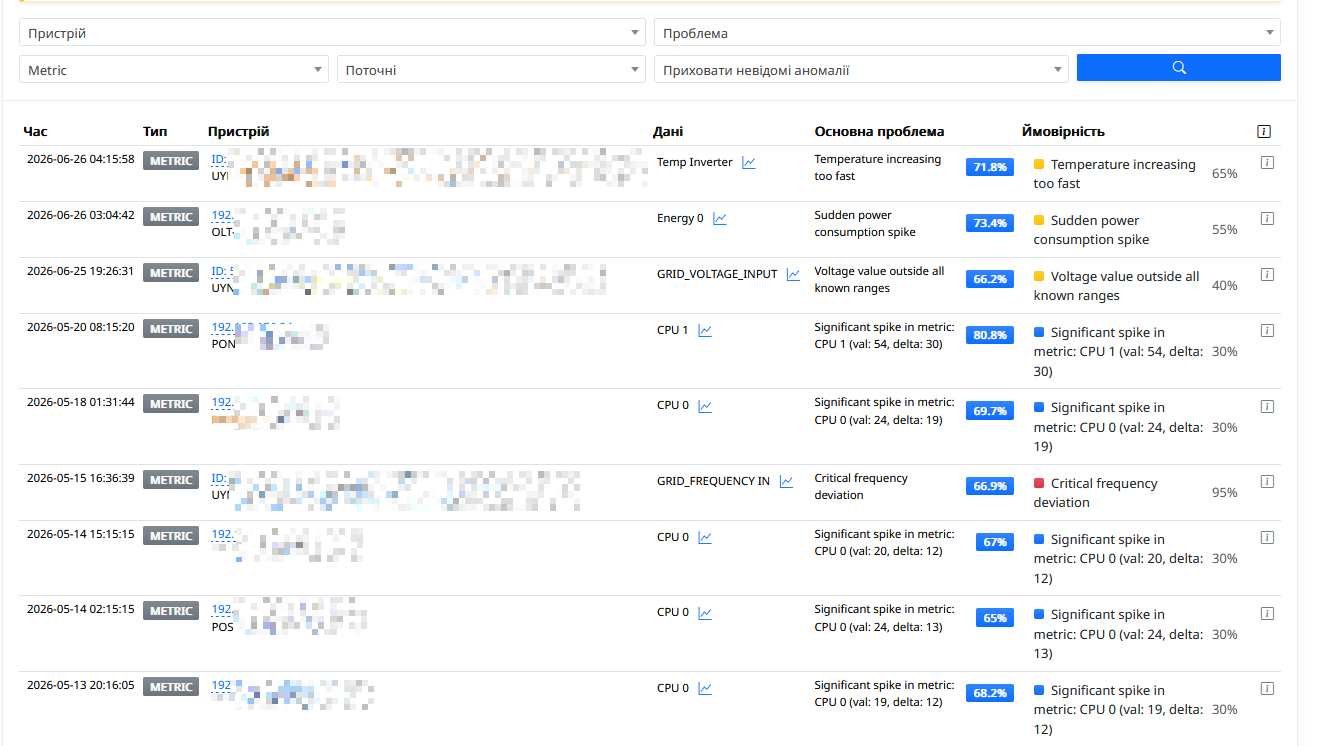
Контроль інженерної інфраструктури
MetricPredictor - Перший модуль відповідає за моніторинг практично всіх системних параметрів обладнання.
Електроживлення та ДБЖ
Система контролює весь ланцюг живлення вузла.
Вона визначає:
- повне зникнення зовнішнього живлення;
- перехід обладнання на акумулятори;
- критичний розряд UPS;
- небезпечні просадки або перенапругу;
- різкі стрибки напруги;
- нестабільність частоти електромережі;
- перевантаження по струму;
- аномальне збільшення споживаної потужності.
Завдяки цьому оператор може заздалегідь побачити проблеми з електроживленням ще до відключення вузла.
Навантаження на обладнання
Система постійно аналізує використання процесора, оперативної пам'яті та накопичувачів.
Виявляються:
- тривале перевантаження CPU;
- різкі стрибки навантаження;
- швидке зростання завантаження процесора;
- нестача оперативної пам'яті;
- заповнення дискової підсистеми.
Важливо, що використовуються гістерезис та аналіз тенденцій, тому система не створює зайвих сповіщень через короткочасні пікові навантаження.
Температура та клімат
Перегрів – одна з найчастіших причин нестабільної роботи обладнання.
Система контролює:
- температуру компонентів;
- швидкість її зростання;
- роботу вентиляторів;
- небезпечну вологість у шафах або серверних.
Окремо визначається ризик термічного розгону, коли навантаження процесора поступово призводить до критичного нагрівання.
Мережеві показники
Для мережевого обладнання аналізуються:
- затримки;
- втрати пакетів;
- CRC-помилки;
- зростання кількості помилок;
- нестабільність бездротового сигналу.
Це дозволяє виявляти деградацію каналів ще до того, як вона стане помітною користувачам.
Контроль стану обладнання
Крім звичайних метрик система також реагує на:
- спрацювання апаратних датчиків;
- відкриття корпусів;
- аварійні сигнали обладнання;
- ситуації, коли обладнання перестало передавати телеметрію.
Навіть відсутність даних розглядається як окрема потенційна проблема.
Аналіз xPON мереж
OnuPredictor - Другий модуль спеціалізується виключно на роботі ONU. Його головна задача – знайти деградацію оптичної лінії ще до того, як абонент почне втрачати зв'язок.
Аналіз оптичного сигналу
Система відстежує:
- поступове погіршення рівня RX;
- нестабільний сигнал;
- сильні коливання потужності;
- різкі просідання RX або TX;
- критично низький рівень прийому.
Замість реакції лише на критичний поріг аналізується історія вимірювань, що дозволяє виявити повільне старіння лінії.
Втрати на оптичній трасі
Окремо розраховуються втрати:
- у напрямку OLT → ONU;
- у напрямку ONU → OLT.
Якщо загасання перевищує допустимі значення або між напрямками виникає значна різниця, система повідомляє про можливі проблеми з волокном, зварками або роз'ємами.
Також контролюється оптичний дисбаланс між показниками ONU та OLT.
Стан лазера ONU
Одним із найкорисніших механізмів є оцінка ресурсу лазера.
Система визначає:
- нестабільне живлення лазера;
- початок деградації;
- природне старіння;
- майже повне вичерпання ресурсу.
Це дозволяє планувати заміну обладнання до його фактичної відмови.
Температура та відстань
Додатково аналізуються:
- перегрів ONU;
- робота при критично низьких температурах;
- надто велика довжина оптичної лінії;
- раптові зміни виміряної дистанції, які можуть свідчити про перемикання або аварійні роботи на трасі.
Моніторинг SFP-модулів
SfpPredictor - Третій модуль призначений для контролю магістральної оптики.
Він підтримує як класичні Ethernet-з'єднання, так і PON-порти.
Система контролює:
- поступове погіршення RX;
- нестабільність сигналу;
- різкі просідання або стрибки потужності;
- критично низький рівень прийому;
- перевищення допустимої потужності передавача;
- температуру SFP;
- напругу живлення;
- деградацію або старіння лазера.
Окремо враховуються особливості PON-модулів, для яких використовуються інші допустимі рівні оптичної потужності.
Інтелектуальні кореляції
Окрім аналізу окремих показників, система вміє зіставляти між собою різні події.
Наприклад:
- якщо одночасно росте температура та навантаження процесора – визначається ризик термічного розгону;
- якщо зникло зовнішнє живлення, а акумулятор UPS майже розрядився – система прогнозує неминуче вимкнення вузла;
- якщо одночасно спостерігається деградація напруги та перегрів – це може свідчити про несправність блоку живлення, а не про зовнішні проблеми з електромережею.
Подібні сценарії значно скорочують кількість хибних спрацювань і допомагають оператору швидше знайти реальну причину несправності.
У сукупності MetricPredictor, OnuPredictor та SfpPredictor формують систему раннього виявлення несправностей, орієнтовану на практичні потреби інтернет-провайдерів. Вона не обмежується контролем порогових значень, а аналізує динаміку показників, історію вимірювань і взаємозв'язок між різними метриками. Це дозволяє виявляти деградацію обладнання, проблеми з електроживленням, оптичними лініями, кліматичними умовами та мережевою інфраструктурою ще до того, як вони вплинуть на якість послуг або призведуть до аварійного відключення.
Спосіб запуску навчання та аналізу через CLI
sudo -u www-data php artisan ml:analyze-metrics
sudo -u www-data php artisan ml:analyze-onu
sudo -u www-data php artisan ml:analyze-sfp
sudo -u www-data php artisan ml:train-metrics
sudo -u www-data php artisan ml:train-onu
sudo -u www-data php artisan ml:train-sfpПриклад CRON
- тренування раз в тиждень для ONU та SFP
- тренування щодня для метрик
- аналіз щодня для ONU
- аналіз що дві години для SFP
- аналіз щогодини для метрик
# === Analyze (every hour) ===
15 * * * * /usr/bin/php /var/www/html/artisan ml:analyze-metrics >> /tmp/analyze-metrics-`/bin/date +\%Y\%m\%d`.log 2>&1
10 */2 * * * /usr/bin/php /var/www/html/artisan ml:analyze-sfp >> /tmp/analyze-sfp-`/bin/date +\%Y\%m\%d`.log 2>&1
# === Analyze (every day) ===
20 2 * * * /usr/bin/php /var/www/html/artisan ml:analyze-onu >> /tmp/analyze-onu-`/bin/date +\%Y\%m\%d`.log 2>&1
# === Train (every night) ===
0 2 * * * /usr/bin/php /var/www/html/artisan ml:train-metrics >> /tmp/train-metrics-`/bin/date +\%Y\%m\%d`.log 2>&1
# === Train (every monday) ===
20 1 * * 1 /usr/bin/php /var/www/html/artisan ml:train-sfp >> /tmp/train-sfp-`/bin/date +\%Y\%m\%d`.log 2>&1
30 1 * * 1 /usr/bin/php /var/www/html/artisan ml:train-onu >> /tmp/train-onu-`/bin/date +\%Y\%m\%d`.log 2>&1Тренування моделей та аналіз даних потребують відповідних обчислювальних ресурсів ЦП та RAM. Будь ласка, забезпечте достатній рівень продуктивності системи для коректного та ефективного виконання зазначених процесів.